The hopefully last release candidate for 7.0 has been released and this is a good moment to introduce the new changes of this major version. This version has been battle tested with existing databases and a lot of new API tests that also covers areas of the product that have not been tested automatically yet.
Removed Orleans dependencies
Squidex from Version 2.0 was based on Microsoft Orleans (https://dotnet.github.io/orleans/). It is framework to create clusters of actors. An actor is something like very small microservice (usually just a class) that lives somewhere in the cluster and receives messages from other actors. An actor is single threaded so it is an easy programming model for developers. Furthermore Orleans manages the lifetime of an actor and ensures that it lives somewhere in the cluster. In Squidex every background process was an actor and also domain objects like apps, schemas, rules, content and assets. The big benefit is that once an actor is loaded from the database every consecutive read is very cheap.
The downside was the additional complexity in the hosting model. It is not that easy to understand Orleans and there are a lot of requirements to the underlaying infrastructure. For example to establish a communication between the cluster members it is necessary that the nodes can make network calls to each other. It is very often not possible in managed hosting environments. You also need a stable cluster, which is also not easy when your nodes do not have a stable host name anymore such as in kubernetes. Futhermore an issue on one node can temporarily cause issues on another nodes, when they need to talk each other.
Therefore the decision has been made to remove Orleans and move back to a tranditional hosting model. You need one worker node now, that receives tasks via a message queue. This message queue is implemented in MongoDB for now, so you do not have any extra dependencies. But the system has been designed to be open for other messaging platforms, such as Google PubSub or Azure Service Bus. Usually the API nodes do not have to talk to the Worker node that much, therefore performance does not matter here and the MongoDB implementation should be sufficient.
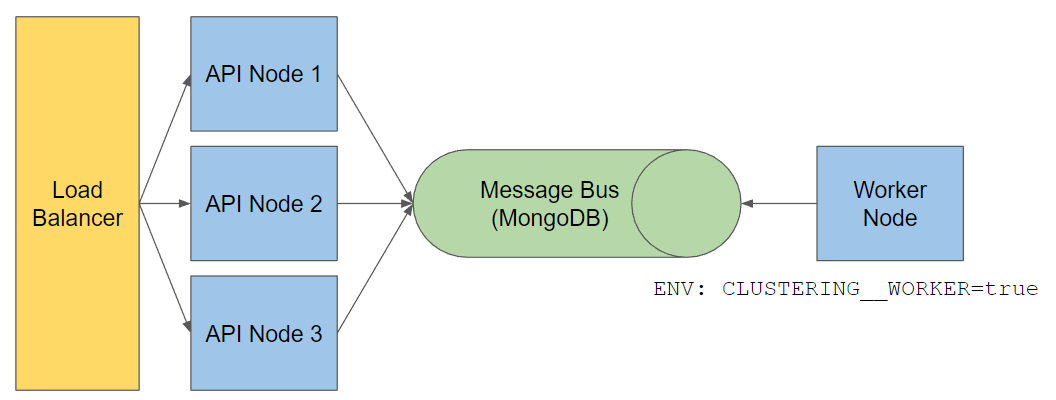 Simple Architecture Model
Simple Architecture ModelMoved to faster JSON serialization
JSON serialization and deserialization is an essential part of any HTTP API and it has huges impact on performance. Therefore most programming languages provide a JSON library, which is either part of the builtin standard library or a community extension. For .NET the inofficial standard was Newtonsoft JSON (https://www.newtonsoft.com/json) for many years. Microsoft has implemented several alternatives over the years but none of them was faster or could offer more features. In 2020 Microsoft has released a new library (System.Text.JSON) which gets more or more attention and is about to replace Newtonsoft JSON. For most use cases it is significantly faster and therefore it was about time to switch to the new JSON library. If you are interested you can read more about the performance in the following blog: https://medium.com/justeattakeaway-tech/json-serialization-libraries-performance-tests-b54cbb3cccbb. You will see that System.Text.JSON is not the fastest JSON library but the alternatives are nieche projects or not maintained anymore
I will talk more about this topic later, because there are some decisions you have to make, when you deploy Squidex.
Dedicated collections for content schemas
Of course we try best to provide optimal performance. But when you have a lot of database records you need indexes that are optimized for your queries. Therefore we introduce a new setting that can be set over the following environment variable: CONTENTS__OPTIMIZEFORSELFHOSTING=true. When this feature is turned on Squidex creates one database per app and one collection per schema in this database. In a shared environment like Squidex Cloud this would create too many database and collections, mtherefore it is turned off by default. Squidex makes a lot of queries to get content items across schemas or even apps. For example when you have a reference field that allows references from multiple schemas. Therefore we create two collections for all content items and two collections per schema now. This means that each published content item is stored in four collections. This makes inserts and updates slower and also increases memory and storage usage. But nothing is free and you have to decide if it is worth or not. If you have only few content items per schemas (less than 1000) you will very likely not see a big difference.
How to migrate to dedicated collections
If you want to test this feature with an existing installation you have to migrate your content to the new structure. You have to execute the following steps:
1. Put your deployment into readonly mode
While we migrate the content we cannot allow changes, because these changes could get lost. Therefore we add the following environment variable to our production deployment and restart all nodes:
MODE__READONLY=true
This will just an error for all create, update or delete operations.
2. Create a new deployment.
Create a new Squidex deployment with only one node with the settings of your production system and the following environment variables:
REBUILD__CONTENTS=true.CONTENTS__OPTIMIZEFORSELFHOSTING=trueSTORE__MONGODB__CONTENTDATABASE=SquidexContentNew
This will delete all your content items and rebuilds them to the new structure. Because we use a new datbase name, the old content items are unchanged and you have no downtime. Of course this should only run on one node and not in parallel.
When the migration is done, remove the first environment variable and restart the new deployment. Otherwise the migration would start again and delete everyhing in your new database as the first stop.
3. Switch to your new deployment
Scale down your previous production deployment and scale up your new deployment.
With this approach you have no downtimes because the old content collections are not changed.
This version does not provide new features, but sometimes it is necessary to do some housekeeping. Please try it out and provide feedback in the support forum. The version is feature complete and will be released soon. This should also solve many downtimes from the past in the Squidex Cloud, because the nodes are independent from each other now easier to scale up automatically.
Appendix: JSON serialization details (for developers)
The MongoDB driver has its own format called BSON (binary JSON) and a builtin serialization library. In many cases you just create a class and tell the MongoDB driver to write this to the database. If you need full control how objects are written to the database you can write custom serializers, which is often necessary for value types, e.g. something like Date, Time, Money and so on, or for custom collections.
Squidex has a few custom serializers and it is a lot of effort to write and test them. Therefore the idea was to leverage the JSON serializer for that. Instead of using the Mongo serialization library as normal, a bridge has been developed to write objects as BSON documents with the Newtonsoft JSON serializer. This was not only faster but also reduced the amount of code and therefore the maintenance costs. It was very efficient because Newtonsoft JSON provides a very extensible programming model.
Unfortunately the same approach was not possible with System.Text.JSON anymore, because the relevant classes (JsonWriter and JsonReader) are not exensible. One alternative was to switch to BSON now but it is easier said than done, because we use different casings. MongoDB uses PascalCase by default and the part of the MongoDB collections that have been generated using the JSON serializer are camelCase. it can be fixed with a lot of configuration and effort. Therefore the old approach of using the JSON serializer is used. It is possible but very slow compared to Squidex 6.0.
In the following screenshot you can see results of a benchmark, where differant alternatives have been tested. The first line is the baseline (Squidex Version 6.0). The Bson serializer would be a litle bit slower, but acceptable (green). The next three lines show the performance of three alternatives that been integrated into Squidex:
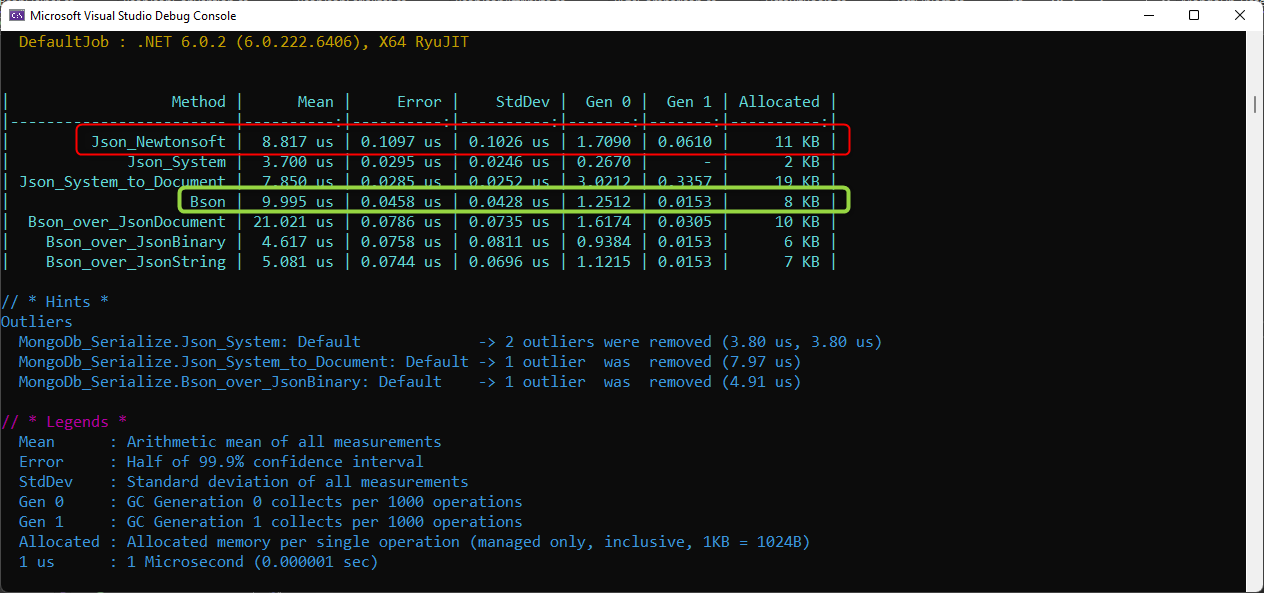 Serialization Benchmark
Serialization BenchmarkThe first approach stores the objects in the same format as Squidex 6.0 and writes them to the database as BSON documents. It is significantly slower than before but easy to read and manipulate when you open the database with a management tool.
With the second approach we write the object to a byte buffer first and store the bytes directly in the database as a field of the root document. It is the fastest approach and almost twice as fast as in Squidex 6.0. You can see an example as the third document in the following screenshot. The problem is that the binary representation is a nightmare when you when you open the database with a management tool.
With the third approach we serialize the object to a string and store the string directly in the database as a field of the root document. This is a meant as a compromise as it provides very good performance but is still easy enough to read when you copy the value from the database to a text editor.
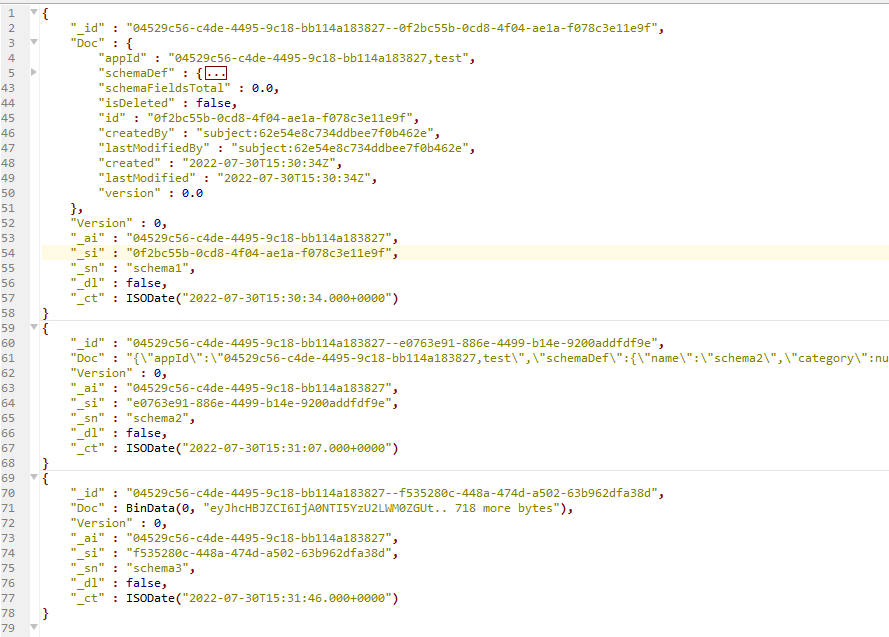 Schemas in MongoDB
Schemas in MongoDBFortunately you can decide on yourself what is best with the following environment variable: STORE__MONGODB__VALUEREPRESENTATION=String|Binary|Document. You can change this environment variable anytime, because it is used for writing only. When we query objects from the database we decide based on what we get from the database which of the three alternatives is used to deserialize an object. The recommendation is to use the String representation. The benchmark has been made with a very large test object and in general all alternatives should work good enough.
Btw: The deserialization benchmark shows similar results:
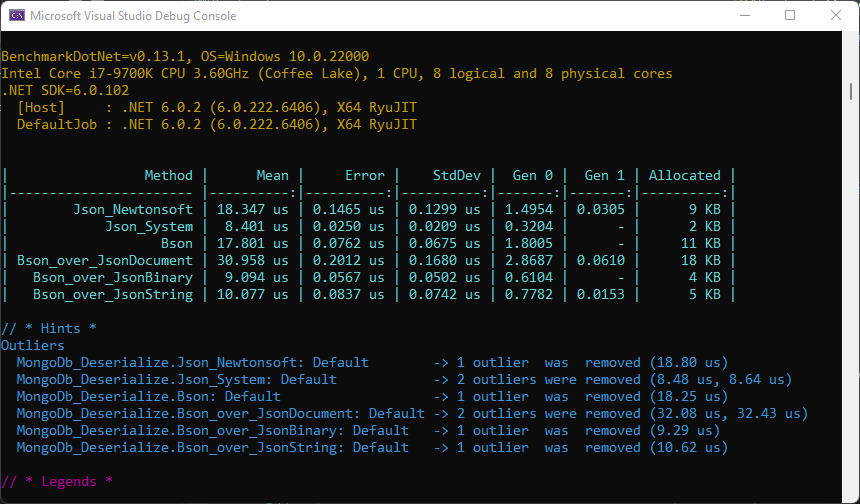 Deserialization Benchmark
Deserialization Benchmark