One of the most requested feature in Squidex are folders for assets and perhaps contents as well and it is in our priority list one of the top-most item. But unfortunately it has not been handled yet, and here is why:
Have I already shown you the mockups for and designs for the asset folders? If not, here they are. We are thinking about this feature since a while now.
 Asset Folders.jpg
Asset Folders.jpgThe reason are the functional and technical challenges.
Functional challenges
Lets start with the requirements. The main reason why this feature has been requested so often is that operation systems and file shares like Dropbox and Google Drive have this functionality. Therefore content editors are used to managed their content with folders and indeed it is a useful feature. You can use folders to build multiple levels of categories. For example you can have a folder for all your product images and another folder for all your logos and if a folder has too many files you can split it up into subfolders. Thats great, but it is has one dimension. If you want to also categorize assets by type or team you have to make a decision as a file can only part of one folder. Therefore we have decided to introduce tags, because you can assign as many tags as you want to an asset.
Lets assume we would have folders with the same behavior like a file system. Then we are facing the following challenges:
Deleting folders
If you have a folder for all your logos and by accident you delete this folder you would also remove these assets from all content items that have a reference to a logo. And there could be thousand of items. So you can actually cause a lot of damage. There are at least three solutions I can think about and probably there are more. And of course you can also combine them:
- Do not allow to delete non-empty folders: We can just decide not allow to delete folders which are not empty. In this case we should a warning and the user has to delete the file manually or perhaps we has to confirm that he wants to delete it. For example by confirming the operations by entering the folder name to an input field or something else that takes a little bit more effort than just clicking a button.
- Introduce folder permissions: We can also introduce folder permissions to prevent certain users from deleting folders. But somebody needs to have the permissions and this person could also cause a lot of damage. So it is potentially not enough to solve this problem, but could be a viable solution.
- Move the assets to an archive: Instead of also deleting the assets we could move them to an archive. So that they are still accessible from content items until they are deleted explicitly.
Rules and events
Another problem is around rules and events. Whenever you make a change in Squidex we create an event, for example the AssetDeleted event. You can handle these events to trigger other processes like updating a full text index or sending a out a slack message that an asset has been deleted. In case you delete a folder you would create a large number of events and it is very likely that the external system is not prepared for that. Either because it cannot handle the load or because we would flood some users with irrelevant information. You don't want to receive thousands of slack notifications because assets have been deleted. Of course we can flag the events when the asset has been deleted as part of the deletion of a parent folder. But whatever we do it would increase the complexity, because you have to handle this flag in the rule system and you can easily forget to handle it or not handle it and end up with an unexpected behavior.
Technical challenges
There are also a lot of technical challenges also. But lets us have a look first how you would with it in a relational database:
The SQL world
If you use a relational database it is very easy to implement a basic folder structure, because you have transactions and cascading deletes. Typically you would model your asset table like this:
| Id | ParentId | Name | IsFolder |
|----|----------|-------------|----------|
| 1 | NULL | Logos | 1 |
| 2 | 1 | Squidex.svg | 0 |
| 3 | 1 | Squidex.png | 0 |
ParentId would be a foreign key to another asset.
If you move a folder or file to another folder you just have to change the parent id:
UPDATE Assets SET ParentId = 1 WHERE Id = 2
If you want to delete a folder, you can just use following statement.
DELETE Assets WHERE Id = 1
With Cascading Deletion the database engine will also delete all children and their children and so on. This approach is called adjacency list, but it also has disadvantages. For example, if you want to retrieve the full subtree of a folder you need multiple joins and it becomes more inefficient with every level in the hierarchy. Getting the full path of an asset is also inefficient because you have to traverse the tree from your asset to the root node to get each folder name and then combine the names to a path.
Another approach is called materialized path, where we store the full path for each asset:
| Id | Path | Name | IsFolder |
|----|-------------------|-------------|----------|
| 1 | Logos | Logos | 1 |
| 2 | Logos/Squidex.svg | Squidex.svg | 0 |
| 3 | Logos/Squidex.png | Squidex.png | 0 |
With this approach we can also get rid of folders and show them when two or more assets have the same path prefix. This is an interesting approach and is also used by big storage providers like Amazon S3 and Azure Blob Storage. Usually you cannot rename assets as the path is used to assign a storage server to an asset and a you might need to move the asset to another server then. All operations and queries can be solved to query assets where the path starts with a prefix. These prefix searches are very efficient because the database engine can use an index for that.
There are other solutions, but these two are the most simple approaches. For further reading I recommend to read this answer on databasestar.com.
DDD and CQRS
But the point is that we do not have a relational database for assets.
We use DDD and Event Sourcing for assets. Each asset is a domain model (aka aggregate root) and when we update an asset we always append events to our event stream and also create a new snapshot that is used in the read model. I highly recommend to read the CQRS introduction by Martin Fowler. We use a stronger consistency model and also update the read store in the command because it was too complicated for us and most our clients to deal with an eventual consistent read model. We do not use transactions to append the events and the read model but as far as I know we never had a problem with this approach.
Furthermore we use Microsoft Orleans for our domain objects. Each domain object is a virtual actor, called grain, that lives somewhere in the cluster. Of course we do note keep all domain objects in memory. A grain will be activated only when needed and if there are no more updates on a domain object it will get deactivated after some time. This adds a little bit of overhead for bulk updates on many grains, because activating them is not free.
This makes it more challenging to implement a folder structure. Furthermore a command can and should only update one domain object. The reason is consistency. It is easy to ensure consistency for one domain object with optimistic concurrency, but if you update multiple domain objects it becomes more challenging.
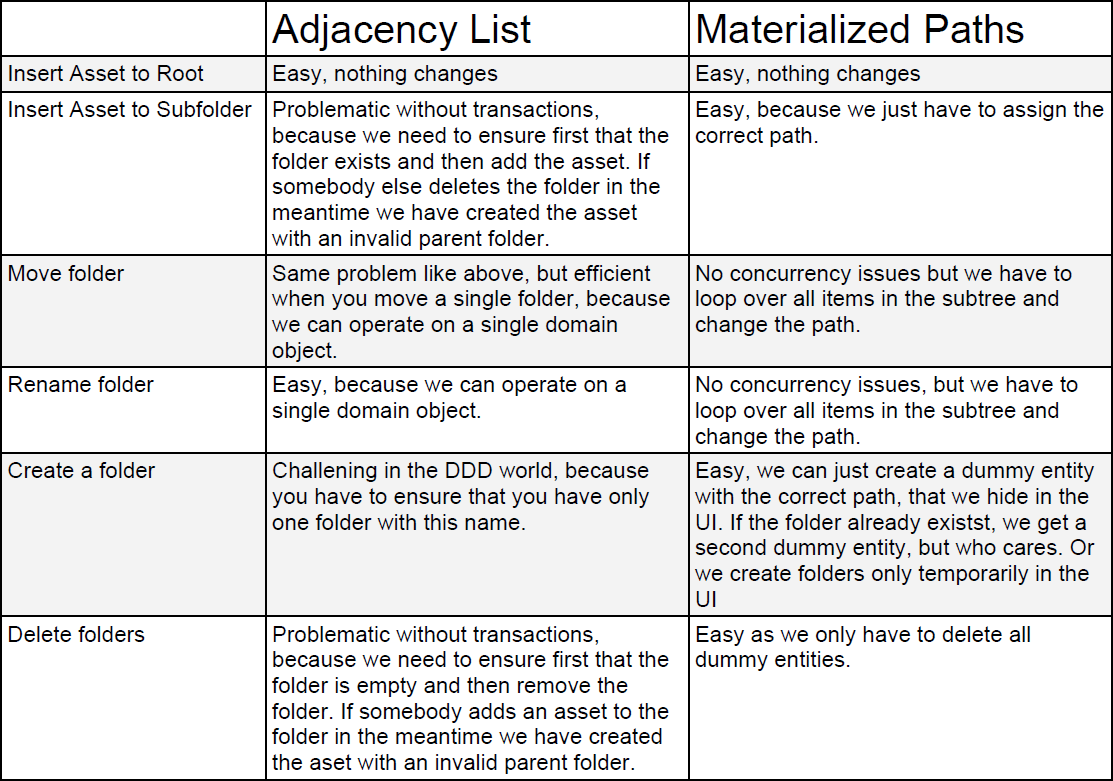
Lets discuss a few use cases with adjacency lists and materialized paths.
 Asset operations
Asset operationsIt seems that we should use materialized paths, but we still have the problem with inefficient updates. We can probably create a parallel structure with just the asset paths which works like a secondary index. It should be easy to implement that we MongoDb and all operations would make use of an index. But this means that the folder structure would not be part of our domain object and would also not create an event if an asset is moved to another folder. It would only work if we do not allow deletions of folders.
As you can see there are no silver bullets and I am open for ideas and suggestions how to implement this feature.